User’s Guide to Memex Explorer¶
NOTE: Memex Explorer is still under active development, and this guide is constantly evolving as a result. For documentation requests, please file an issue and we will endeavor to address it as soon as possible.
Application Structure¶
The goal of Memex explorer is the bring together the functionality of several applications in a seamless way, in order to assist the user in searching the deep web for domain specific information. Memex Explorer has integration with several applications, providing a front-end to various crawlers and domain search tools.
- Web Crawling
- With Memex Explorer you can create, run, and analyze Nutch and ACHE crawls. The crawl operation is heavily abstracted and simplified. Users provide a list of seed URLs to start the crawl, and in the case of ACHE’s targeted crawling, a machine learning model to determine the relevancy of crawled pages.
- Dataset Analysis
- Memex Explorer allows you to upload a large number of files, which will be analyzed by Tika and placed into our Elasticsearch instance. Tika will exctact metadata from these documents, giving you a better overview of them.
- Domain Discovery Tool
- Through the use of Domain Discovery Tool, the user can search for content in the web and build data models based on clustering algorithms. The user can search the web and highlight relevant and irrelevant pages, and DDT will produce data model files, which you can use with Ache crawls in Memex Explorer.
- DataWake
- DataWake is a server and firefox plugin that tracks your search investigations. It keeps track of where you search, so that “trails” can be built out of the information that you gather. These trails can be converted to seeds lists in Memex Explorer, and can be used in both Nutch and Ache crawls.
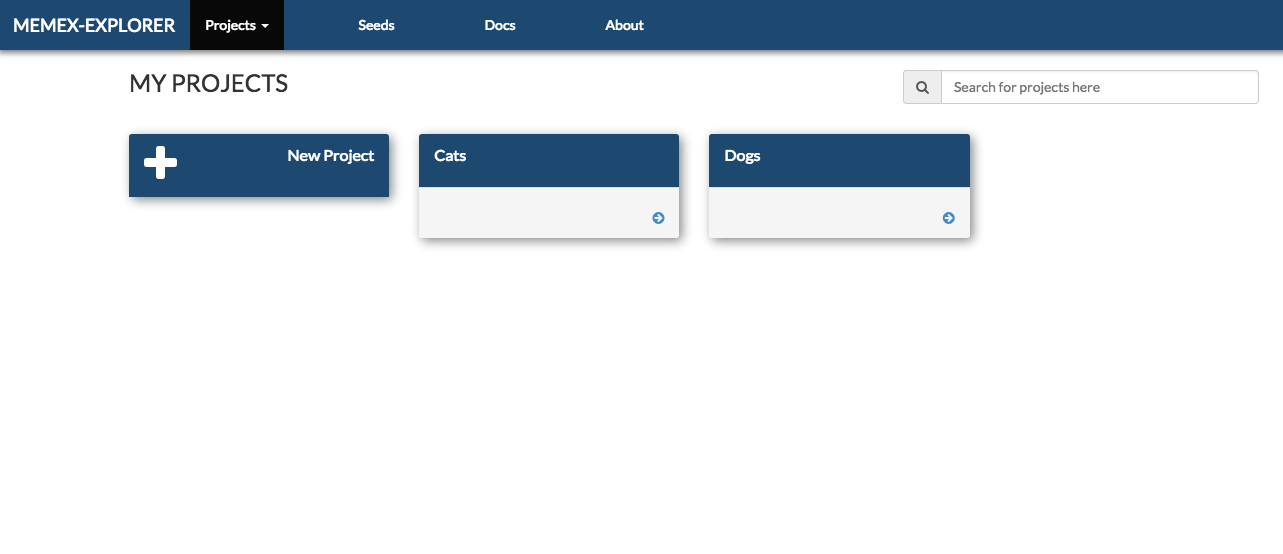
Home Page¶
The landing page lists the currently registered projects. All the capabilities of Memex Explorer live under this project abstraction.
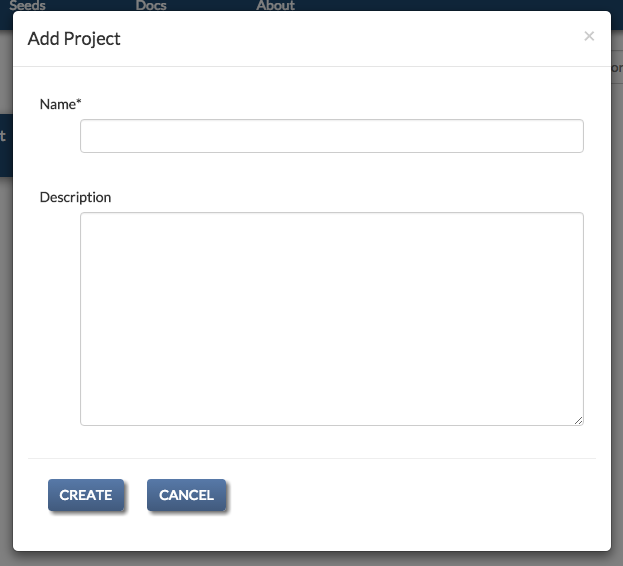
Creating a project just requires adding a name and an optional description.
Project Page¶
The project page lists the currently available services in Memex Explorer. These services can all be access from the project page.
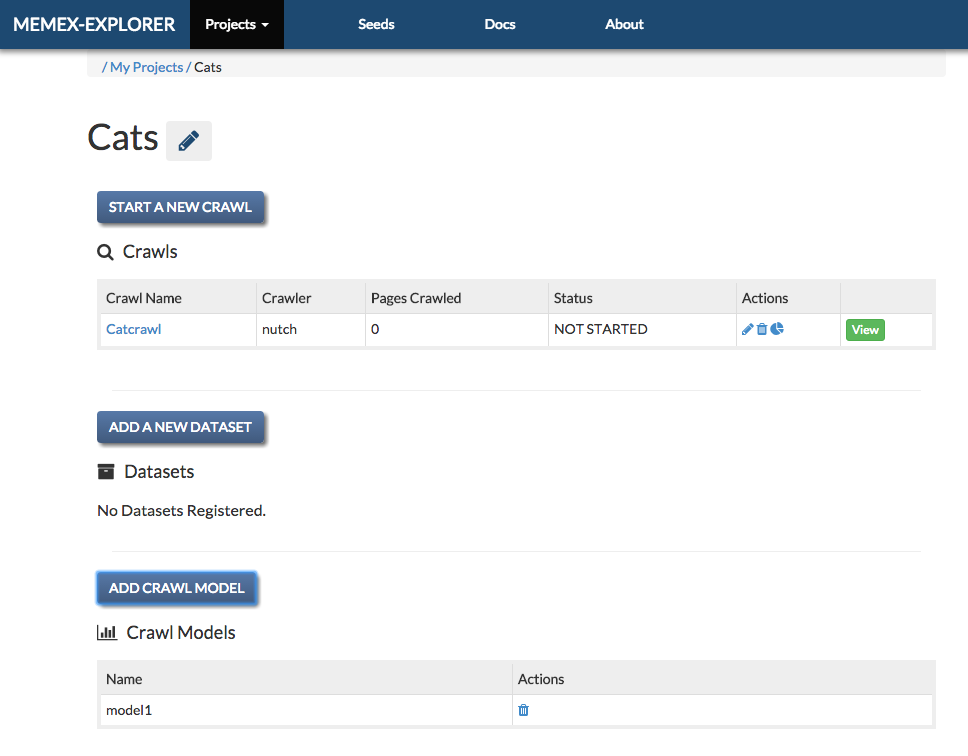
Registering a Crawl¶
To register a new crawl, click the “Add Crawl” button above the Crawls table. This will open a popup for adding crawls. If necessary, you can also create seeds list objects and crawl models from the same form.
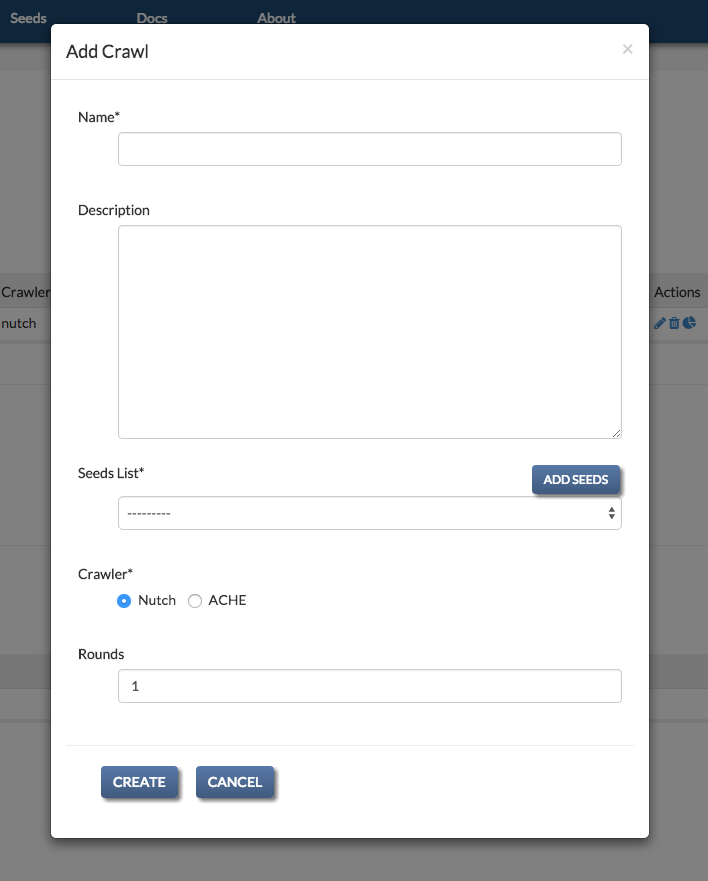
For both crawls, you have to supply a seeds list object, which contains the list of urls to be crawled. The seeds list object can be created from the Add Crawl form.
For ACHE crawls, you have to specify a crawl model for the crawl, which can also be added from the Add Crawl form.
Registering a Crawl Model¶
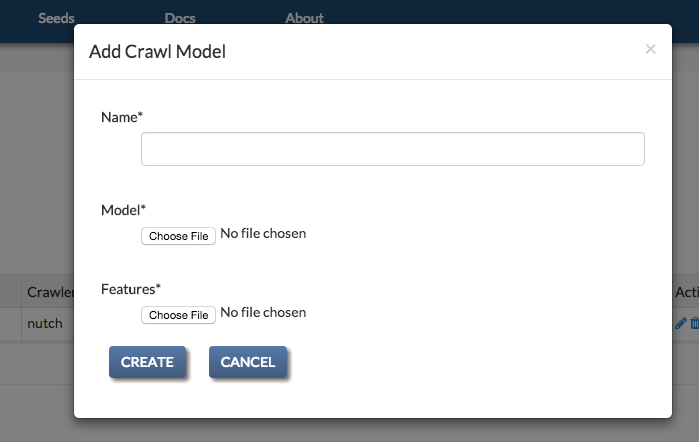
ACHE crawls require a Crawl Model to power the page classifier. The model consists of two elements: a “model” file and “features” file. These can be generated by following the instructions on the ACHE GitHub page.
To register a new crawl model, click on the “Add Crawl Model” button in the Crawl Models header. This will bring up the crawl model creation popup. Models can also be added from the Add Crawl form by selecting “ache” as a crawler.
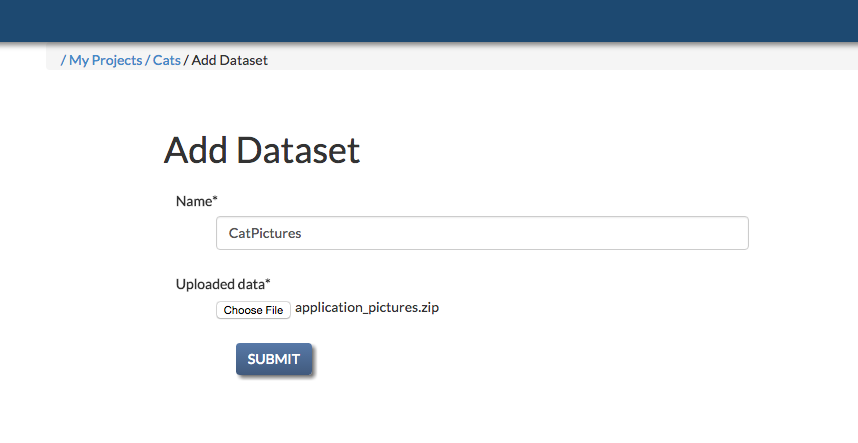
Uploading Files and Dataset Creation¶
With Memex Explorer you can create indices by uploading zipfiles of important documents. Memex Explorer will analyze these documents with Tika. You can then easily access the documents from the local Elasticsearch index, and incorporate them into other data analysis tools. You can create the dataset by clicking “Add Dataset” on the project page.
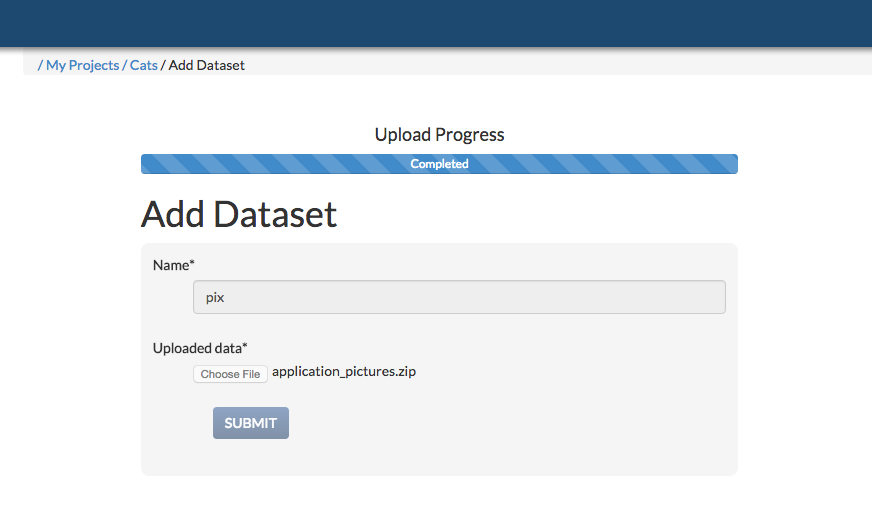
The add dataset page has a progress bar, and when your dataset has been successfully uploaded, you will get a success message and an alert to close the page. If you attempt to close the page before the files have been successfully uploaded, you will get an alert warning you to wait until the page is done uploading.
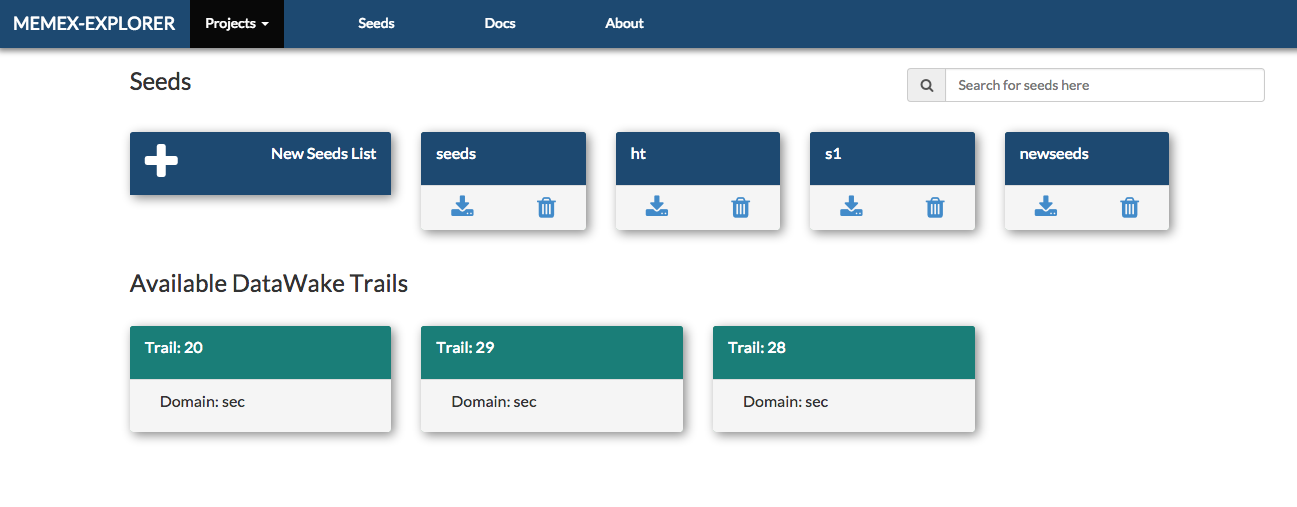
Seeds List Page¶
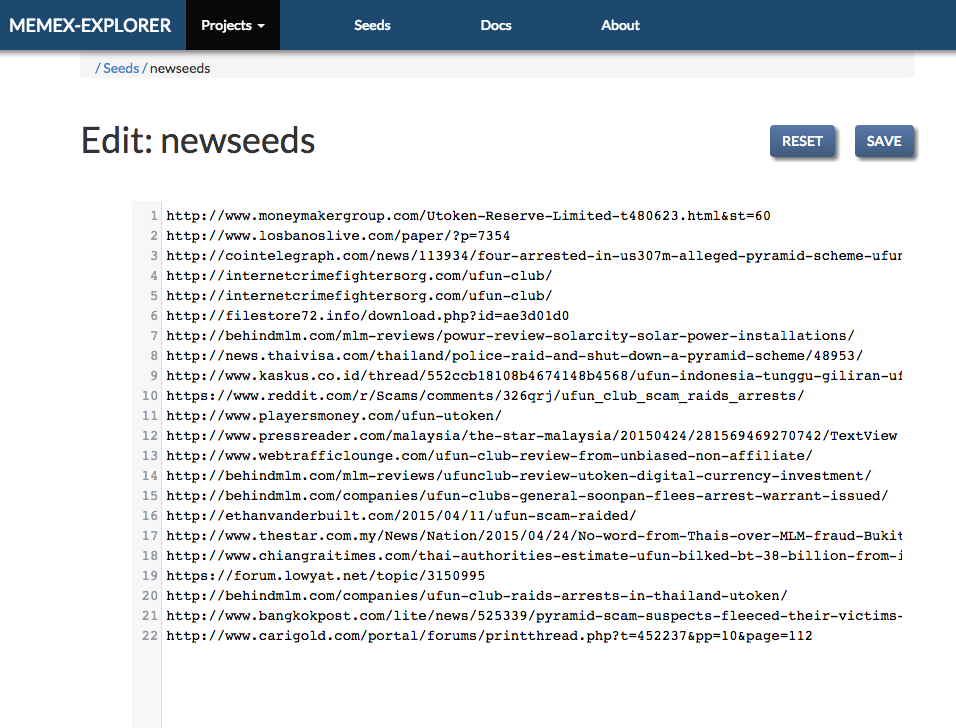
Seeds for crawls are independent of projects. They are created by clicking on the “Seeds” button on the navbar. From the seeds list page you can create seeds lists from files, text, or from datawake trails. You can also edit the seeds on a separate page. In addition, you can delete and download any of the seeds objects that you create. This is the seeds list page:
Registering a Seeds List¶
Each crawl requires a seeds list object. Ache requires the seed list in a textfile, whereas Nutch requires a seeds list injection. The seeds list object handles both of these requirements. It creates a file for Ache and contains fields for injecting seeds through the Nutch REST Api. All seeds objects can be added on the “Add Crawl” popup. This is the seeds list form.

Seeds require a valid name, and either a file or URLs placed in the textarea below. If any of your seeds are invalid, you will get a form error, and all the invalid urls will be highlighted.
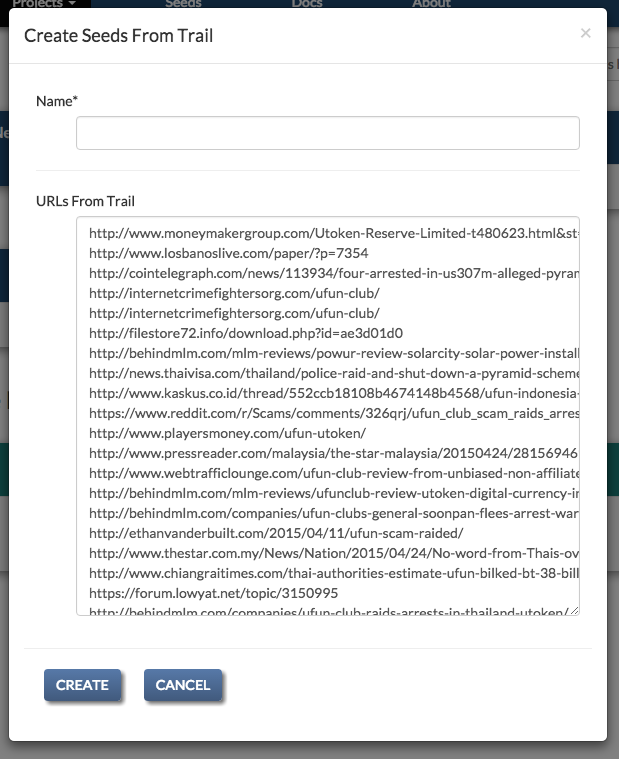
Creating a Seeds List from a DataWake Trail¶
If you are using DataWake, and Memex Explorer has access to the index used by DataWake, you will be able to create seeds lists from DataWake trails. To create a seeds list, all that is required is a valid name. After you create the seeds list, you can edit it just like any other seeds list.
Editing a Seeds List¶
Once you have created your seeds list, you can edit through our built in editor. This editor allow you to change the content of your seeds list, by adding or removing seeds. It will also validate all of the URLs and display the ones which contain errors.